Yesterday I hosted the Aston Corpus Linguistics Symposium, a one-day programme of talks by researchers using corpus methods to address a range of interesting linguistic questions. This was my first time attending an in-person academic event for two years, since Covid-19 forced us to move online. During this period, many professions embraced online communication (especially video conferencing) like never before and, in (corpus) linguistics, we saw many excellent online conferences. Many of us recognised that events which may previously have attracted a few dozen in a lecture theatre could reach hundreds or even thousands online, and at relatively little expense. These and other benefits (and challenges) of online conferences have been discussed, for instance, by the organisers of some of 2020’s successful online conferences, among others. Earlier this year, I discovered the benefits for myself when I co-organised (with Gavin Brookes and Niall Curry) the BAAL/CUP seminar Corpora in Applied Linguistics: Broadening the Agenda, which was originally (optimistically?) envisaged as a face to face event and became an online one. An event with a planned face-to-face attendance of 30 became an online event attracting nearly 200.
Now, as Covid-19 restrictions have relaxed somewhat in many places, we face the question of how (or whether) to incorporate our new online practices into conferencing when we no longer need to operate in isolation. In preparing for yesterday’s symposium, it became clear to me that another ‘new normal’ may be on the horizon; namely hybrid academic conferences. I say ‘new’, but of course hybrid events had already been going on long before Covid-19. In corpus linguistics, an example I can think of off the top of my head is the UCREL Corpus Research seminar series at Lancaster University, which had been live-streaming their seminars on Twitter (via Periscope) for quite some time before the pandemic. I’m sure there are many other examples too.
But there is a difference between allowing an online observer a chance to be a fly on the wall and facilitating substantive participation. Not that there is anything wrong with being a fly on the wall, of course – there is still much to be gained from simply being able to watch someone give an excellent talk on an interesting topic. But there are also benefits to interactivity and meaningful participation as an active member of the event. Covid-19 forced us to develop expertise in facilitating meaningful participation online quite quickly, but the new challenge lies in merging our newfound good practices in the online context with the offline practices we had been used to for so long prior to the pandemic.
Enter the Aston Corpus Linguistics Symposium. Back in January, I launched the Aston Corpus Linguistics Research Group, as part of a College-wide restructuring of our research centres and research groups. Throughout 2021, we held online meetings and developed an overview of the array of corpus research activities going on across the university. Over the summer, I decided that we should showcase this activity publicly and started discussing ideas for an event with my colleague Daniel McAuley (who has sadly since left Aston). I really wanted to host a face-to-face event, but I also wanted to offer as many people as possible to chance to attend, so I decided to keep the Zoom component that had worked nicely for us with the BAAL/CUP seminar back in April.
So, how was it done? A few notes:
Promotion and registration
I used the free version of WordPress to build a pretty basic but functional website to promote the symposium. I shared the website on Twitter as well as relevant mailing lists. The website linked to the registration site which was housed on Eventbrite, again for free. On Eventbrite, I created two ticket types (in-person and online) and set individual capacity limits for both ticket types (70 and 1,000 respectively). In-person tickets ‘sold out’, while 800 of the online tickets went too (again demonstrating the appetite for online participation).
Video conferencing technology
Online participants accessed the symposium via Zoom. For the most part, their experience (in terms of access) would have been the same as a regular online conference. The only difference really is that, rather than there being one ‘screen’ representing the hosting stream of the event, there were several, offering different shots of the room (one screen for the slides, another for a live feed of the lecture theatre, etc.).
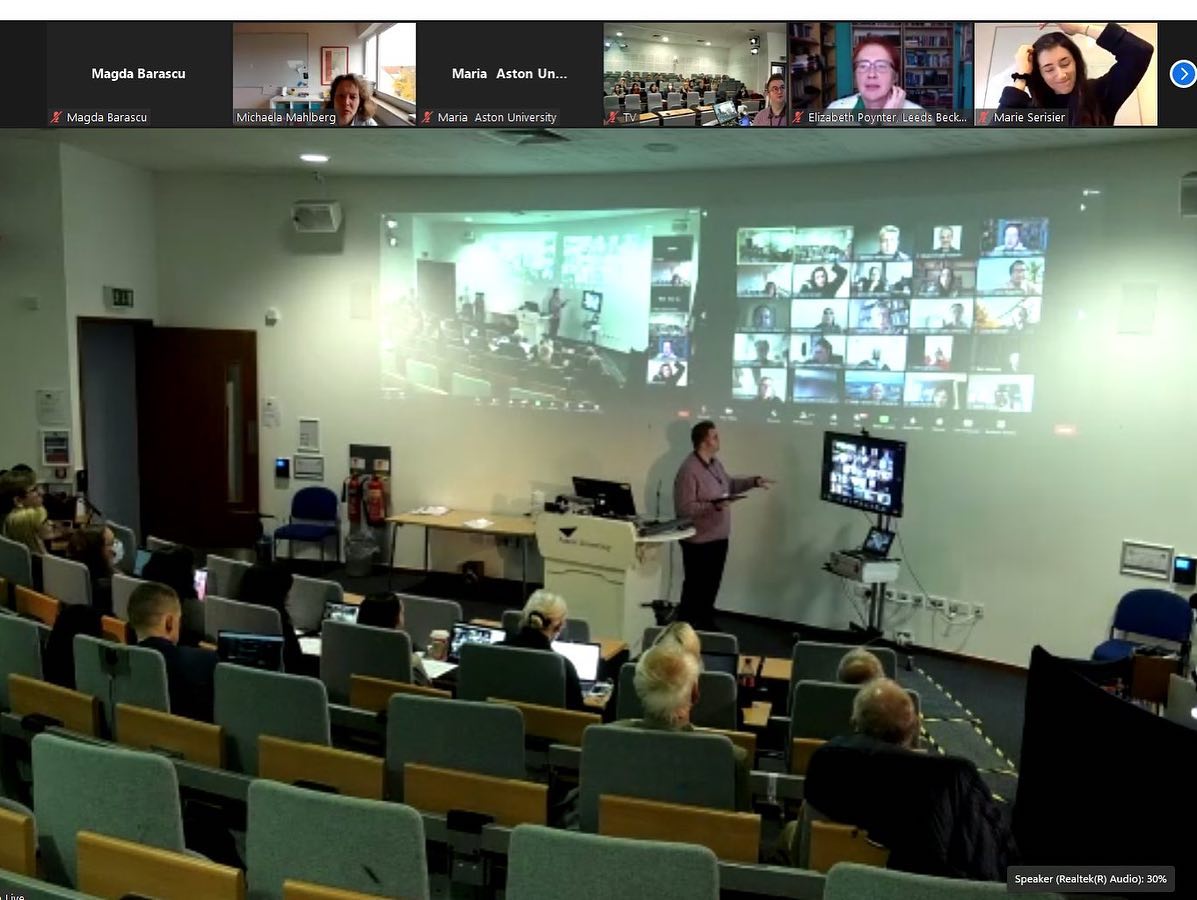
Venue
I booked a regular lecture theatre that was then ‘transformed’ into a hybrid environment by a videographer, who was recommended by the conference support team. Upon arrival at the venue yesterday morning I felt I was entering a TV studio. There were many lights and cameras dotted around the place as well as a TV monitor allowing interaction with the Zoom audience. I think there were six or seven cameras in total; some at the back of the lecture theatre giving a wide angle of the room; some at the side offering close-up shots of the speakers (and audience members during Q+As); and also one on the TV monitor, allowing direct address of the Zoom participants.
Presentations
Some may disagree, but I prefer live presentations. Those who prefer pre-recorded (online) presentations are justified in doing so, based on the risk that something may go wrong with the technology and disrupt the event. Luckily (in my experience at least), such technical issues are rare and so I’m prepared to take the risk to go live. Originally, this debate would not have been relevant for the symposium, as all speakers were due to be physically present (and so pre-recording would not have been an option anyway). However, one of our speakers couldn’t attend in person and ended up giving their talk online. The great thing about being set up as a hybrid event anyway meant that the speaker could simply log in to Zoom, share their slides and give their talk, treating the face-to-face participants to a cinematic experience. All other presentations were given live by speakers who were present in the lecture theatre.
Timings
During the symposium, I acted as ‘chair’ for all of the talks. Traditionally, the role of a chair is simply to moderate the Q+A sessions, selecting from a sea of raised hands (or coming up with a question to ask when there are none from the audience). They are also responsible for ensuring that the event runs on time and that speakers don’t overrun (a common occurrence!) – although on that point there seems to be philosophical variation about just how forcefully a chair should exert their power to keep speakers to time. Some hold up cards, counting down the speaker until they reach a card that says ‘STOP!’, which is then usually ignored by the speaker anyway. In extreme cases the chair may actually bring the talk to a halt completely when the speaker runs out of time. Such measures may be defensible in conferences with parallel sessions, where several simultaneous streams of talks need to stay ‘in sync’ so that participants can move around between talks without missing anything. Yesterday’s symposium comprised just a single stream of talks, so I chose to allow a little more flexibility, and some talks ran over for a few minutes. No one seemed to mind.
What I did not account for were the delays at the beginnings of each section of the programme. After each break, I would return to the lecture theatre, put on my radio mic and then wait to be told that we had ‘gone live’ again for the online audience. This process did remind me of a TV studio preparing to make a live broadcast (I was almost tempted to erect light-up APPLAUSE signs for our in-person audience). This did mean that each session started a few minutes late, as the technical set up required lots of checking the ensure everything was in order before going live.
Audience participation
The face-to-face audience would have had a similar experience to any other offline event, aside from being able to see faces of those in the Zoom audience who had turned on their cameras projected onto the wall throughout. Otherwise, they participated in all the traditional ways: raising their hands to ask questions, gossiping in the coffee breaks, and getting lost on the way to the loos.
The online audience used the Zoom chat to ask technical questions to the support team and any other discussion that was not formally part of the Q+A sessions. For the Q+A, they were asked to submit questions to an online tool called Slido. This is basically one of those online polling tools that allows you to collate questions (and display them if you wish). I was initially reluctant to use Slido (or any other polling tool) as, quite honestly, I didn’t see the point and I guessed that participants would be used to just asking questions in the chat or using the ‘raised hand’ button. But I was persuaded to give it a go when it was brought to my attention that, if I used Slido, I could stand there with a tablet and field questions as they appeared, seamlessly transitioning between offline and online questions. So I decided to give it a go, and actually it worked really well. Rather than having to ask a colleague sitting at a laptop to tell me about any questions in the chat, I could simultaneously chair both the face-to-face questions and the online questions without any disruption to the flow of the Q+A sessions. This is something I would definitely love to see again in future hybrid events.

Costs
In order to attract as many people as possible, I decided to make the symposium a free event. I was able to do this with the support of the Aston Centre for Applied Linguistics (within which the Aston Corpus Linguistics Research Group is housed), which made available £500 towards the event. The rest of the funding came from my personal ‘new starter’ research fund, which is a little pot of money that was allocated to me when I joined, available to spend on research activity within my first two years at Aston. Admittedly, this would have run out long ago if not for Covid-19, as I would have spent it on flights and hotels to go to conferences in person! As was the case, I still had some money left to be used up before March, so I thought the symposium would be a good investment.
Overall, I estimate that the event cost around £1,500. About half of this went on the room bookings and catering for the in-person participants at our university’s conference centre (discounted by 50% for internally-funded events). The other half went towards the technical support for hybrid (£500) and other bits and pieces, like extending the Zoom capacity beyond 100 users.
Is hybrid here to stay?
Based on the positive reception of yesterday’s event I would say yes. However, a few recommendations…
I learned by doing this that the online element of hybrid should not at all be overlooked, and also it should be done with expert technical support. In my case, I had that expert support, and my recommendation to not attempt it without that support is based on how badly it probably would have gone had I attempted it without! This sort of support does of course require some money, but really not as much as I thought it would be, and I don’t see any reason why others couldn’t do something similar, especially if they decide to charge even a small registration fee to cover the costs.
Another recommendation would be to ensure that you have plenty of volunteers to help monitor and moderate the online conversation. I had overlooked this issue until a few days beforehand, when the conference support team asked me how many volunteers I had arranged to work on the Zoom chat (I had none!). Luckily, I have many excellent and supportive colleagues who very happily stepped in to help with little notice. They proved invaluable, as having hundreds of online participants creates a lot of queries and potential technical issues to be addressed.
Related to this point is a recommendation based on something I didn’t do that I wish I had. Early yesterday morning I woke up to several emails from participants with last minute questions (mostly where is the Zoom link?). The participants had emailed me as I had told them to contact my email address with any queries (it was more of an insincere politeness thing, you know – don’t hesitate to get in touch if you have any questions! – that you write when you are confident no one will have any questions). People did have questions, and they kept coming all day. Since I was busy chairing (and presenting) I was unable to respond quickly enough to the questions. So next time, I would definitely arrange for a generic event email that can be accessed by several people (the same people who moderate the online conversation, preferably) so I could be freed up to focus fully on the face-to-face chairing work.
Aside from these fairly minor points though I think the event went very well, and there’s not much I would have done differently. I really enjoyed creating a shared offline/online space and I actually found the transitions between the two to feel quite natural and not at all jarring. I would happily organise / attend more hybrid events in the future, long after Covid-19, as the benefits of access and wider dissemination of research are plainly evident. Saying this, I will always prefer attending events face-to-face, and I’m not ashamed to say that, although I had not at all missed the simultaneous feeling of exhaustion and hyperactivity brought about by university catering coffee.
 Robbie Love is a PhD student at the ESRC Centre for Corpus Approaches to Social Science (CASS) at Lancaster University, where he spent four years working on the Spoken British National Corpus 2014 project.
Robbie Love is a PhD student at the ESRC Centre for Corpus Approaches to Social Science (CASS) at Lancaster University, where he spent four years working on the Spoken British National Corpus 2014 project. Harry Strawson is a writer living in London and contributed recordings to the Spoken British National Corpus 2014.
Harry Strawson is a writer living in London and contributed recordings to the Spoken British National Corpus 2014.
